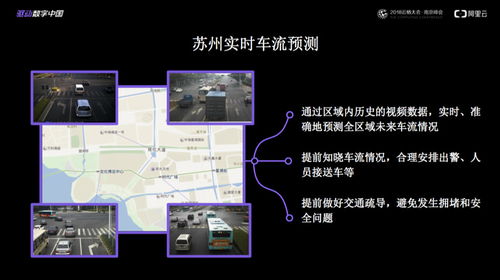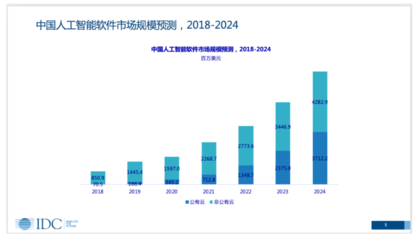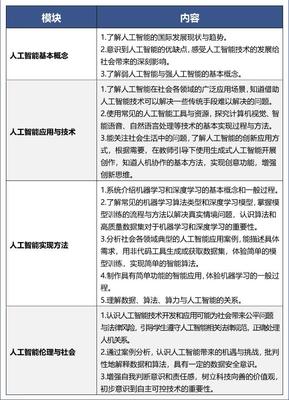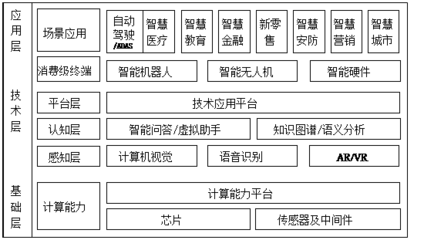
在人工智能技术浪潮席卷全球的今天,奇绩创坛创始人兼CEO陆奇博士指出,我们正站在一个关键的历史转折点:人工智能不仅重塑应用层,更将驱动计算体系的核心——芯片和底层基础软件——经历一场根本性的重构。这场变革的深度与广度,堪比个人电脑和移动互联网的诞生,并将为未来的技术创新奠定全新的基石。
一、 传统计算范式的局限与AI的颠覆
传统计算架构(以CPU为中心)及其软件栈,是围绕确定性、顺序执行的通用计算任务设计的。人工智能的核心——尤其是深度学习——本质上是概率性的、数据密集型、高度并行的计算。这导致了传统架构在能效、带宽和计算效率上的巨大瓶颈。训练大规模模型所需的惊人算力,以及推理应用对实时性和低功耗的苛刻要求,都呼唤着从硬件底层到软件栈的全新设计。
二、 芯片架构的革命:从通用到领域专用
为了满足AI计算的需求,芯片设计正从“通用计算”加速转向“领域特定架构”(Domain-Specific Architecture, DSA)。
- AI加速芯片的崛起:以GPU为先驱,随后涌现出TPU、NPU以及各类初创公司的专用AI芯片。它们通过大规模并行处理单元、优化的内存层次结构(如高带宽存储器HBM)和针对矩阵乘加运算的专用电路,实现了数量级的性能与能效提升。
- 软硬件协同设计的深化:AI芯片的成功,越来越依赖于与上层算法和框架的紧密协同。芯片不再是孤立的产品,而是为特定AI工作负载(如Transformer模型)深度优化的计算平台。
- 异构计算成为主流:未来的计算系统将是CPU、GPU、AI加速器及其他处理单元(如DPU)的复杂组合,如何高效地调度和管理这些异构资源,成为核心挑战。
三、 基础软件栈的重构:新的“操作系统”
硬件的巨变必然要求软件栈的彻底革新。AI时代的基础软件,其核心任务是高效管理和释放异构硬件的澎湃算力,并为开发者提供简洁、统一的抽象接口。
- 编译与运行时系统的进化:传统编译器主要针对CPU优化。AI时代需要全新的编译器(如MLIR、TVM),能够将高级的AI模型描述(如PyTorch、TensorFlow模型)自动、高效地映射到底层多样的硬件指令集和内存架构上,并进行复杂的图优化、算子融合和内核生成。
- 编程模型的抽象与简化:目标是让算法研究员和开发者无需深究硬件细节,就能高效利用算力。这需要构建更高级、更灵活的编程抽象和中间表示层。
- 系统软件的重新定义:资源调度、内存管理、任务编排等系统软件功能,需要从服务通用进程,转向服务以数据流和图计算为核心的AI工作负载。分布式训练框架(如Megatron-LM、DeepSpeed)便是这一趋势的体现,它们本身已成为庞大模型得以训练的关键基础设施。
- 工具链与生态的竞争:正如移动互联网时代iOS与Android的竞争,AI时代的基础软件栈也正围绕主流框架(PyTorch等)和硬件平台(NVIDIA CUDA等)形成生态。谁能提供更友好、更高效、更开放的软件栈,谁就能吸引更多的开发者和应用,从而赢得生态主导权。
四、 挑战与机遇并存
这场重构浪潮带来了巨大机遇,也伴随着严峻挑战:
- 技术复杂性:软硬件协同设计的门槛极高,需要横跨算法、架构、编译、系统等多领域的顶尖人才。
- 生态壁垒:现有巨头(如英伟达凭借CUDA生态)已建立起强大的护城河,新玩家需要提供颠覆性的价值才能破局。
- 标准化与碎片化:硬件架构的多样化可能导致软件生态的碎片化,推动不同层次接口的标准化(如ONNX模型格式、MLIR编译器基础设施)至关重要。
- 安全与可靠性:新的软硬件栈必须构建起从底层到应用层的安全体系,确保AI系统的可靠与可信。
陆奇博士的观点清晰地揭示了人工智能发展的深层逻辑:它不仅仅是一种算法创新,更是一场深刻的计算体系革命。芯片与基础软件的重构,是释放AI全部潜能的必由之路。对于中国科技产业而言,这既是弥补传统领域短板的压力,也是在全新赛道实现引领的绝佳机遇。抓住这场体系性变革的核心,大力投入芯片架构创新与基础软件研发,构建自主可控且繁荣的AI计算生态,将是在智能时代赢得主动权的关键所在。